Google Unveils DiffusionGemma — the Fastest AI Model with a Trade-off
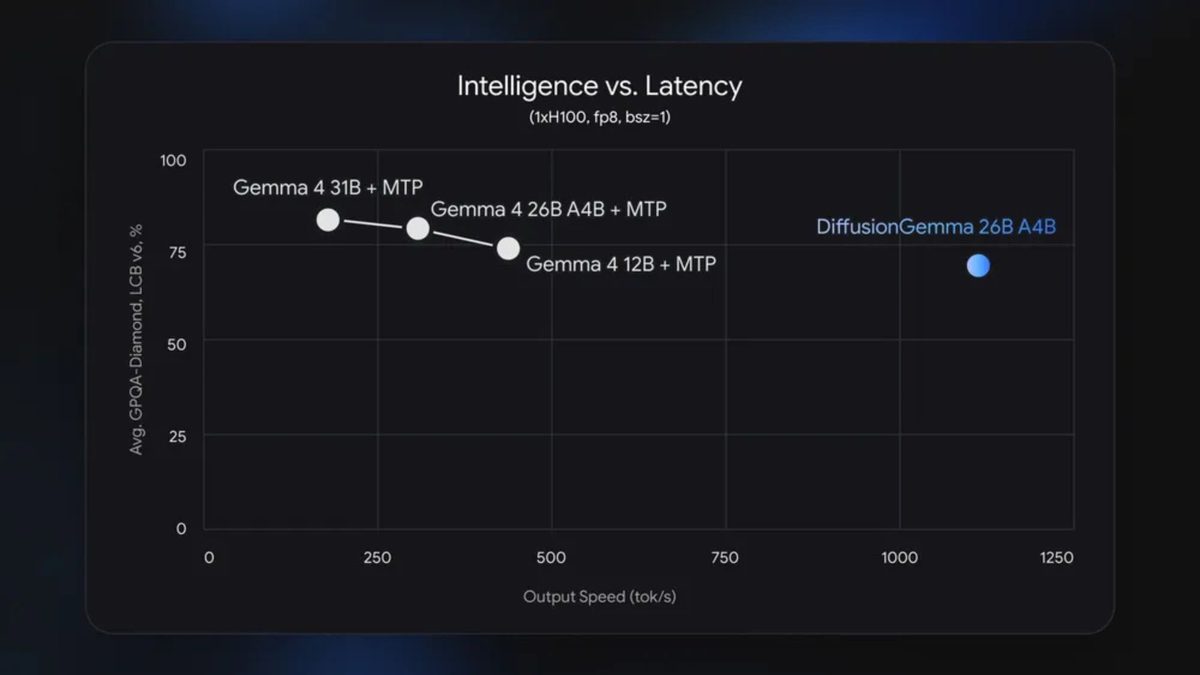
Photo: Android Authority
Quick answer
Google launches DiffusionGemma, an experimental AI model that generates text four times faster than traditional solutions by processing blocks in parallel, though with reduced quality.
Google has released DiffusionGemma, an experimental artificial intelligence model that introduces a fundamentally new approach to text generation. Instead of sequentially producing text word by word, as traditional models like Gemma 4 do, DiffusionGemma generates an entire text block at once and then refines it through multiple iterations. This method significantly speeds up the process but results in lower output quality.
According to Google, DiffusionGemma can generate text up to four times faster than standard autoregressive models. On high-performance hardware like the NVIDIA H100, the model achieves speeds exceeding 1,000 tokens per second, while on the RTX 5090, it reaches around 700 tokens per second. This makes it a promising tool for applications where speed is critical, such as real-time systems or interactive assistants, rather than those requiring perfect accuracy.
The model is built on a Mixture-of-Experts architecture with 26 billion parameters but utilizes only about 3.8 billion during operation. This reduces computational resource requirements, allowing the model to run on high-performance consumer GPUs with quantization, requiring a minimum of approximately 18 GB of VRAM. DiffusionGemma is particularly effective for structured tasks, such as filling in code gaps, working with JSON formats, or solving logical puzzles.
However, the new model has its drawbacks. The quality of the generated text is inferior to that of traditional solutions like Gemma 4. The output may be less coherent and precise, limiting DiffusionGemma’s applicability in tasks demanding high accuracy. Google positions it as an experimental tool for scenarios where speed and rapid feedback are prioritized over perfect quality.
The model is available to developers and researchers under the Apache 2.0 license. It is not intended to replace existing models like Gemini or Gemma but rather demonstrates an alternative approach to text generation, where speed and efficiency take precedence over quality.
Common questions
- How does DiffusionGemma differ from conventional AI models?
- Unlike traditional models that generate text sequentially, DiffusionGemma creates an entire text block at once and iteratively refines it. This speeds up generation but results in lower output quality.
- For which tasks does DiffusionGemma perform best?
- The model excels in structured tasks such as code completion, JSON processing, logical puzzles, or mathematical patterns. It can resolve inconsistencies within a single generation cycle.
- What are the hardware requirements for DiffusionGemma?
- The model uses approximately 3.8 billion of its 26 billion parameters and requires around 18 GB of VRAM when quantized. It runs on high-performance GPUs like the NVIDIA H100 or RTX 5090.
Dzen feed: /feed/dzen.xml · RSS: /feed.xml